Structure Beats Scale
What happens when you let a cheap model critique an expensive one
This post is the story behind the research. If you want the full paper with methodology, statistics, and raw data: Structure Beats Scale on GitHub.
This shouldn’t have worked.
I took a model that costs a tenth of a cent per call — Mercury 2, a diffusion-based reasoning model that nobody was talking about for code review — and I asked it to critique code written by Claude Sonnet, a model that costs 40 times more. Then I let Sonnet fix the code based on the cheap model’s feedback.
The cheap reviewer made everything better. On competitive programming problems — the hard benchmark, where Sonnet alone solves 52.0% — my review pipeline hit 85.1% pass rate at $0.14 per problem. Brute-force generation — just throwing seven independent attempts at the wall — hit 82.8% but costs $0.22. The structured approach was cheaper with a higher point estimate. The pass rate gap on competitive programming isn’t statistically significant (more on that below), but the cost advantage is real.
On a separate, easier benchmark — MBPP, 25 short Python programming problems — the gap blew open: 90.7% versus 46.0% (p=0.002). Seven attempts with no review barely moved the needle from baseline. One attempt with a cheap review nearly doubled it.
I wasn’t expecting that. I had a hunch that figuring out what’s wrong before trying again would beat just rolling the same dice more times. But I also expected the cheap reviewer to be the weak link. Mercury 2 isn’t even close to Sonnet’s quality. Over 52% of its reviews came back as plain text instead of the JSON I asked for.
And it still worked. A model that can’t reliably follow a formatting instruction can apparently reliably find bugs in code written by a model 40 times its price.
Let me back up and explain how I got here.
Mercury 2 Changed the Math
The objection to structured review has always been twofold: it costs too much and it takes too long. Adding a review step means more API calls, more dollars, more latency. If the review model runs at the same speed and price as the generator, the economics don’t work.
Mercury 2 broke both objections at once. It’s a diffusion-based language model from Inception Labs — instead of generating tokens one at a time (autoregressive, the way every other LLM works), it generates through parallel refinement. The founding team includes Stefano Ermon from Stanford, who pioneered diffusion models for images. Same idea, applied to language. The result: ~1,000 tokens per second versus ~89 for Haiku. That’s not a marginal improvement. That’s a different category.
A Mercury review call costs about $0.001 to $0.003. A Sonnet generation call costs $0.02 to $0.12. That’s a 10-40x cost difference. And because Mercury generates in parallel instead of sequentially, the latency for a review is roughly 1-2 seconds versus 15-25 for a comparable autoregressive model. I haven’t formally benchmarked wall-clock time for the full pipeline yet, but the speed difference is why I picked Mercury in the first place. If cost and speed were the objections to structured review, they both just went away.
Suddenly I could afford to run multiple reviewers on every generation and still come in under the cost of a second generation API call. The question flipped from “can I afford to review?” to “what’s the best structure for my budget?”
So I built a pipeline and tested it. A few thousand times.
3,121 Runs on 110 Problems
Here’s what I actually did: 17 experimental conditions across 6 strategy families — baseline, generation-only, review-heavy, debate, iterative fix loops, and hybrid generation-plus-review. Sixty competitive programming problems (30 calibration, 30 held-out), plus 25 HumanEval and 25 MBPP problems. Three generator models: Claude Sonnet, Qwen 2.5 Coder 32B, and DeepSeek V3. Total: 3,121 runs. Total cost: about $134.
The pipeline has three roles. The generator (Sonnet) writes code. The reviewer (Mercury 2) reads the code and identifies bugs — without ever seeing the test suite. The fixer (Sonnet) gets the original code plus all review feedback and writes a revised solution.
The reviewer never sees the generator’s reasoning trace. Fresh context every time. Context isolation is the whole point. The reviewer can’t anchor on intent because it never saw the intent.
The reviewer sees no reasoning trace, no shared assumptions. My hunch was “you have an off-by-one error in your boundary check” is more useful than “try again.”
The Pareto Frontier
When you’re optimizing two things at once — pass rate and cost — some strategies are strictly better than others. A strategy is “Pareto optimal” if nothing else beats it on both dimensions. The set of those strategies forms the Pareto frontier: the best you can do at any given price point. Anything not on the frontier is wasting money, leaving performance on the table, or both.
Here’s the headline result on the calibration set (30 competitive programming problems, 3 replicas each):
| Strategy | What It Does | Pass Rate | Cost/Problem |
|---|---|---|---|
| C0 (baseline) | 1 generation, no review | 52.0% | $0.038 |
| C9 (debate) | 1 gen + 3 Mercury reviews + fix | 74.8% | $0.058 |
| C16 (brute force) | 7 independent generations | 82.8% | $0.221 |
| C13 (hybrid) | 3 gens + 2 reviews each + fix | 85.1% | $0.141 |
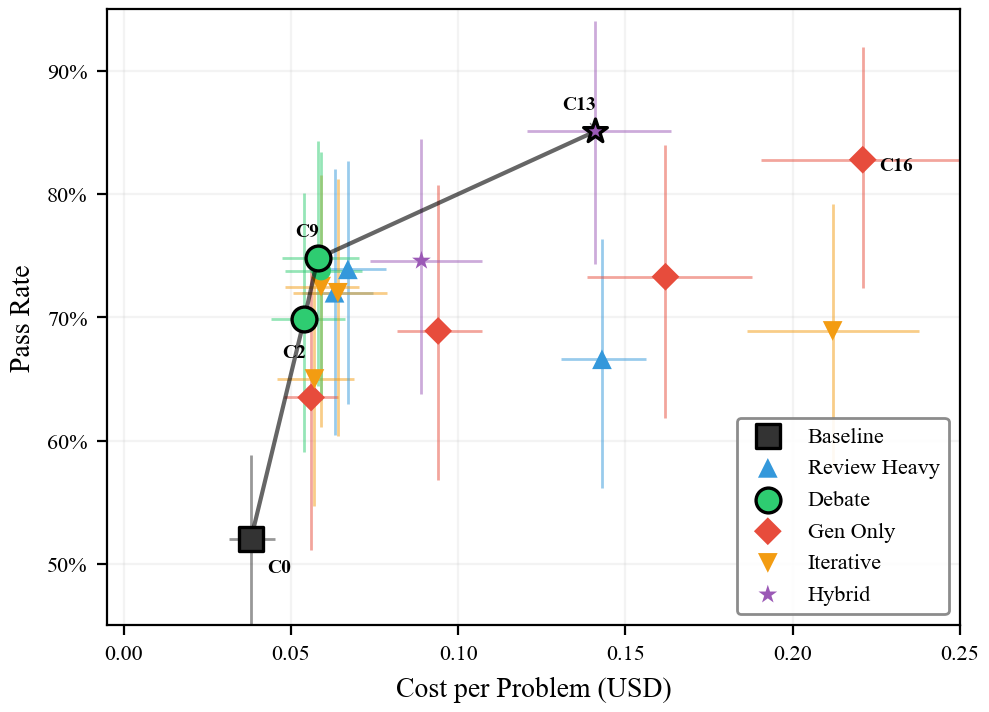
C13 beats C16 on both dimensions. Higher pass rate. Lower cost. That’s Pareto dominance — not a tradeoff, a straight win.
I want to be honest about the statistics: the 2.3 percentage point gap between C13 and C16 is not statistically significant (p=0.53, n=30 problems). If C13 and C16 cost the same, I couldn’t tell you which one is better. But they don’t cost the same. C13 is $0.141 and C16 is $0.221 — that’s a 36% cost difference, and cost isn’t a random variable with confidence intervals. It’s measured directly from API billing. So even if the pass rates are statistically tied, C13 is strictly cheaper. You’d need C16 to be significantly better to justify paying more for it, and it isn’t. That’s what Pareto dominance means in practice: when one option is definitively cheaper and at least tied on performance, statistical significance on the performance axis is the wrong bar. The ordering C0 < C9 < C13 holds across every condition I tested.
And that’s a big deal.
No generation-only condition ever lands on the Pareto frontier. Not best-of-2. Not best-of-5. Not best-of-7. Every point on the efficient frontier involves structured review. Bootstrap analysis (10,000 resamples) confirms the endpoints are stable: C0 appears 100% of the time, C13 appears 99.5%. But the middle of the frontier is softer — C9 only appears 72.8% of the time, meaning it falls off in more than a quarter of resamples. The frontier is solid at the extremes and directional in between.
It Replicates
An important caveat about the calibration results above: the experimental design was adaptive. Results from earlier studies influenced which conditions I tested later, because I was trying to figure out what works. Five of the 17 conditions reuse data from those earlier studies. That means the calibration results carry a multiple-testing burden beyond what my Bonferroni corrections cover — they should be treated as hypothesis-generating, not confirmatory. The held-out, cross-model, and cross-domain experiments are the independent tests.
The held-out set is where I tested the hypothesis.
On 30 new problems the models had never seen: C0=38.7%, C9=51.5%, C13=55.6%. The ordering holds. C0 versus C13: p=0.002, significant after Bonferroni correction. The core finding survived contact with unseen problems.
Rank correlation between calibration and held-out orderings across all tested conditions: Spearman rho=0.786 (p=0.036). The relative ordering of strategies is stable even when absolute pass rates shift.
Two things that didn’t replicate: C2 (debate with only 2 reviewers) dropped to 35.7% on held-out — worse than baseline. And best-of-2 generation (C3) barely beat baseline at 40.1%. The strategies that were marginal on calibration data didn’t survive replication. The frontier simplified to C0 → C9 → C13.
The Qwen Surprise
If the finding only holds for Sonnet, it’s a finding about Sonnet, not about inference-time compute allocation. So I swapped in two alternative generators. DeepSeek V3 to test a different capable model, and Qwen 2.5 Coder 32B to find the floor — how weak can the generator be before the review pipeline stops helping?

Qwen answered that question immediately. It cannot solve a single competitive programming problem on its own. C0 = 0.0%. Zero. But run that same model’s output through a Mercury review and Sonnet fix pipeline, and it reaches 53.2% (C13). That looks like a miracle — until you ask who’s actually doing the work.
That’s not the interesting part. The interesting part is why it works.
I ran a matched-fixer experiment to find out. Instead of always using Sonnet as the fixer, I let each generator fix its own code. Qwen generates, Mercury reviews, Qwen fixes. DeepSeek generates, Mercury reviews, DeepSeek fixes.
Qwen collapsed to 0% across the board. The entire gain had been Sonnet solving the problems. Qwen couldn’t fix its own code even with good review feedback. The review pipeline didn’t make Qwen better — it routed Qwen’s failures through a capable fixer.
DeepSeek told a different story. DeepSeek matched-fixer: C9=41.9%, C13=51.8%. The gains held. DeepSeek could read the reviews and act on them. The review structure genuinely worked — Mercury identified real bugs, and DeepSeek could fix them without Sonnet’s help.
The practical takeaway: structured review works, but the fixer has to be capable enough to act on the feedback. The best bug report in the world doesn’t help if the model can’t write the fix.
The MBPP Result

On MBPP (25 problems), the separation is the most dramatic in the entire study: C0=40.0%, C13=90.7%, C16=46.0%. That’s C13 vs C16: p=0.002. C16 — seven independent generations with no review — barely beats a single generation. Seven attempts at problems Sonnet struggles with, and brute force buys you 6 percentage points. Review buys you 50.
On HumanEval, there’s a ceiling effect — Sonnet already scores 83.4% at baseline, and C16 scores identically at 83.4%. Seven attempts with no review beats one attempt with no review by exactly nothing. The problems Sonnet fails on HumanEval, it fails across all 7 attempts. But review pushes to 95.4%.
Generation scaling provides zero marginal value when the generator is already near ceiling. Review still helps.
Why It Works: Quality, Not Just Selection
There’s an obvious objection: maybe C13 just benefits from best-of-3 selection with extra steps. Three generations give you three shots. The reviews might be doing nothing.
The pass@1 data says otherwise. Pass@1 measures whether a single pipeline — one generation plus its reviews and fix — produces a passing solution, before any cross-pipeline selection.
C13 pass@1: 0.689. C6 (best-of-3 generation, no review) pass@1: 0.522. A 16.7 percentage point gap.
Both conditions generate three independent solutions. But C13 reviews each solution before fixing. The review step makes each individual pipeline more likely to succeed, not just the overall ensemble.
Generation-only scaling increases the number of independent attempts. Structured review increases the probability that each attempt succeeds. That’s the difference between buying more lottery tickets and getting better at the game.
What Doesn’t Work
More reviews on the same code doesn’t help. I tested 1, 5, and 10 Mercury reviews on a single generation (C1, C5, C8). Pass rates: 72.0%, 66.6%, 73.9%. No meaningful relationship. The reviewer sees the same code every time. Its ability to find bugs doesn’t improve with repetition.
More fix iterations plateau fast. Four review-fix loops (C10) and eight loops (C12) produce nearly identical results: 72.5% vs 72.0% (p=0.808). The fix loop converges within about 4 iterations. Grinding doesn’t help.
More than 3 debate reviewers adds nothing. C9 (3 reviewers) = 74.8%. C15 (5 reviewers) = 73.8%. Three is the sweet spot.
Temperature tuning can’t rescue brute force. I tested C16 at temperatures 0.4, 0.8, and 1.0. Pass rates: 46.4%, 47.0%, 48.9%. A 2.5pp range. The argument that “C16 would win at a different temperature” is empirically false.
What I Don’t Know
Thirty problems per benchmark, 2-3 replicas per condition. The effective sample sizes produce wide confidence intervals — standard errors range from 3.6% to 8.8%. C13 has the highest intra-cluster correlation (0.74) and the lowest effective N (~36), which means the condition I’m most enthusiastic about is the one with the least statistical precision. I report this because it’s true, not because I have a solution.
I also only tested competitive programming, HumanEval, and MBPP — all function-level problems with pre-written test suites. Whether structured review helps with the kind of messy code engineers actually write — multi-file changes, ambiguous requirements, integration bugs — is an open question. SWE-bench would be the right place to test that. I haven’t yet.
My “debate” conditions aren’t real debates. The reviewers don’t respond to each other. They evaluate independently. True multi-turn adversarial debate might produce different results.
And I can’t fully decompose the review effect from the fixer effect. I ran a fixer ablation where Sonnet received the problem statement and Mercury’s bug list but not the generator’s code — and it still hit 48.6% on held-out problems, compared to 55.6% with the code. The fixer can solve many problems from scratch given only the review as context. That means a chunk of the pipeline’s gains may come from Sonnet’s independent capability, not from the review-and-fix loop specifically. The paper calls the review “a structured problem description supplement, not necessarily a fix guide for specific code.” I don’t have a clean control where the fixer gets the code but no review, so the full decomposition remains open.
The $134 Experiment
The total cost of this entire study — all 3,121 runs across 7 experimental phases — was approximately $134. That’s the cost of one decent dinner. Mercury 2 made the review calls so cheap that I could test 17 different inference-time compute allocation strategies on 110 problems across 3 models for the price of a mediocre date night.
A year ago, this experiment would have cost thousands. The economics of doing research on LLM behavior are changing as fast as the models.
What This Means If You Build Things
The practical recommendation is simple: have LLMs review code. If you have budget for more than one LLM call per problem, spend it on review structure, not more independent samples.
The optimal architecture from this study is C13: generate 3 independent solutions, have each one reviewed twice by a cheap reasoning model, fix each one based on the reviews, and pick the best. It costs 36% less than generating 7 samples with no review — and matches or exceeds it on pass rate across every benchmark I tested.
But there’s a prerequisite the data is clear about: the fixer has to be capable enough to act on the feedback. The review pipeline amplifies competent models. It doesn’t rescue incompetent ones.
The full paper, all 3,121 raw result files, and the analysis scripts are on GitHub. Every number in this post has a JSON file behind it. Check my work.
Generation scaling is the path of least resistance. Review scaling is the Pareto frontier. The evidence says: figure out what’s wrong before you try again.