The Only Limit Is Noticing
Seven days ago I wrote that the main thing that reliably matters in AI-assisted development is quality gates. Nineteen sprints across three projects, five falsification experiments, and the punchline was “just run your damn tests.”
But I left out the harder question. If implementation velocity is effectively solved — if a PM with domain knowledge and a Claude Code session can ship tested, linted, type-checked software in 15-minute sprints with gates that pass on the first try 82% of the time — then what’s actually scarce?
Yesterday I got my answer. I built Nexa, a compliance-aware Kubernetes scheduler, from scratch — four binaries, 137 unit tests1, 93% coverage, Helm charts, a threat model, and a market analysis — in ten hours. First commit at 7:14 AM, last commit at 5:16 PM.
That’s not the interesting part.
The interesting part is why I think nobody had built it yet.
The Problem Nobody Solves at the Right Layer
If you run sensitive workloads on shared Kubernetes clusters — healthcare data, financial models, classified computations — you have a compliance gap that no existing tool addresses cleanly. (Full competitive analysis in the repo.)
OPA Gatekeeper validates policy at admission time. Too early — the scheduler hasn’t chosen a node yet. Kueue, Volcano, YuniKorn handle batch scheduling: when to run, not where to run safely. Native taints and affinities give you binary per-pod rules with no audit trail, no org isolation, and no concept of whether a node has been sanitized since the last tenant’s workload ran on it.
The gap is at scheduling time — after admission, before node binding. That’s the exact moment you know which nodes are available and which workload needs placement. And nobody enforces compliance there. 84.1% of AI infrastructure CapEx is cloud-based — much of it on shared infrastructure. Somewhere in every one of those environments is a compliance officer asking “can you prove that workload X never ran on the same node as workload Y?” The answer today is “no” or “we built dedicated clusters at 3–5x the cost.” That’s not just a compliance problem — it’s a utilization problem. Every dedicated cluster is stranded capacity that can’t be shared.
The companies building frontier models are feeling this hardest on the inference side. When you’re serving Claude or GPT to a European healthcare customer on shared GPU clusters, GDPR requires you to prove where that data was processed, SOC 2 requires you to prove it was isolated, and the enterprise contract requires an audit trail. Both Anthropic and OpenAI have completed SOC 2 Type II audits. California’s SB 53, effective January 2026, adds another layer for frontier model developers specifically — they must publish cybersecurity frameworks documenting infrastructure protections, with civil penalties up to $1M per violation. But the scheduling layer that actually decides which workload lands on which node still has no standardized compliance tooling.
Why? Because it’s a genuinely awkward intersection. The people who understand Kubernetes scheduling don’t usually understand HIPAA. The people who understand HIPAA don’t know what a Filter/Score plugin interface is. And the hyperscalers have no incentive to make multi-tenant compliance easy, because dedicated clusters are more profitable. I’ve spent years building infrastructure at Meta and in enterprise security startups like Elevate Security, so when I asked myself “how do schedulers handle HIPAA compliance and data sovereignty audits?” and the answer was “oh shit, they don’t,” the gap was obvious.
That’s not a technical problem. That’s a noticing problem.
What Nexa Actually Does
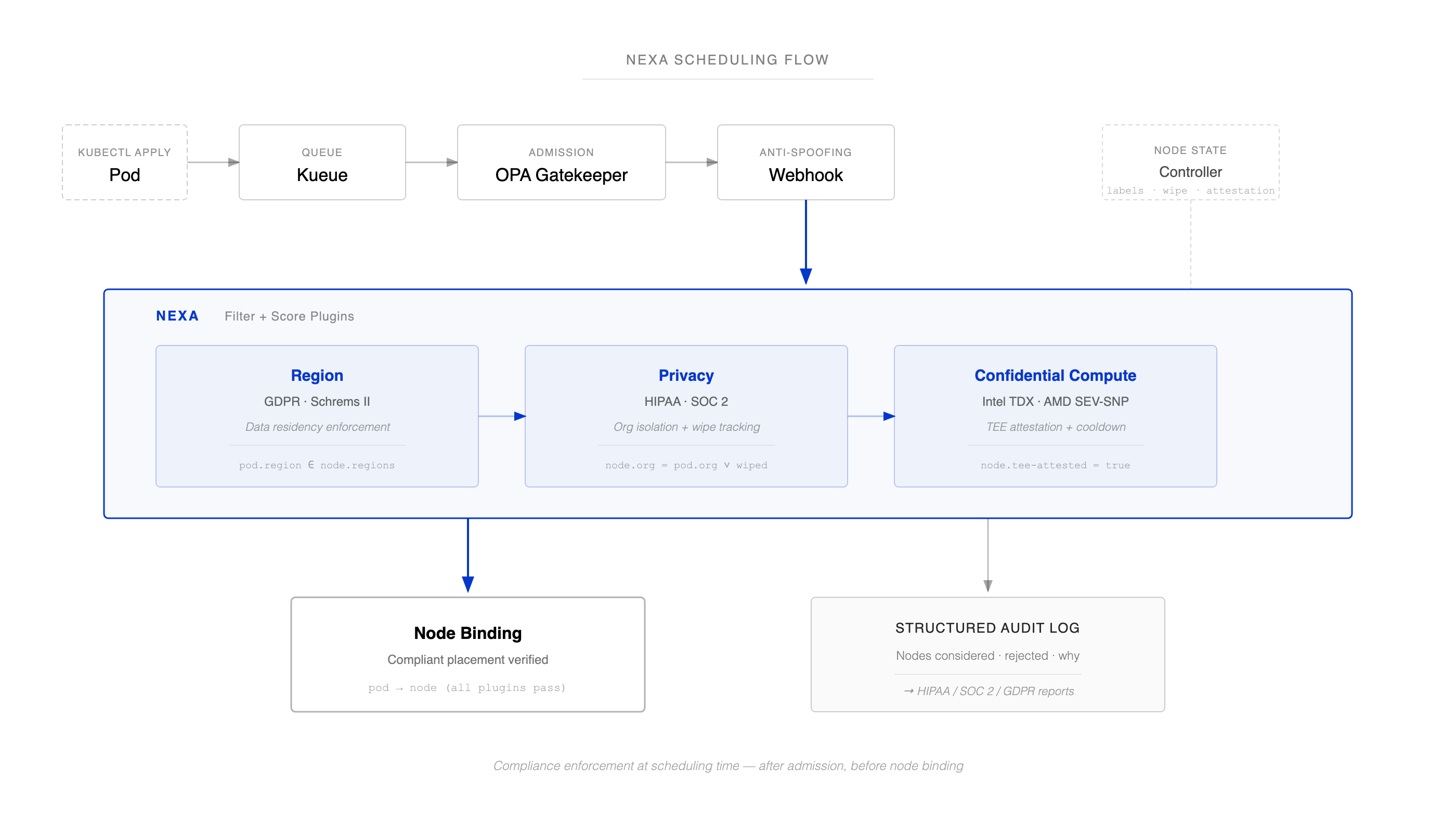
Nexa (the thing I made in a day) is four binaries that snap into Kubernetes’ Scheduling Framework:
A scheduler running three plugins (Filter + Score). Region enforces data residency — GDPR, Schrems II. Privacy enforces org isolation — high-sensitivity pods only land on nodes wiped since the last tenant, tracked by dynamic nexa.io/last-workload-org labels. Confidential Compute ensures pods requiring hardware trust envelopes (Intel TDX, AMD SEV-SNP) land on nodes with TEE capabilities and configurable cooldown periods. (Note: these are CPU-side protections. GPU workloads are not covered — see the uncomfortable gap below.)
A node state controller that watches pod lifecycle events and patches node labels in real time — marking contamination state, recording which org last ran there, and running remote attestation via a bridge service that retrieves hardware quotes from the node’s TEE (e.g., /dev/sev-guest) and submits them to a real attestation provider like Azure MAA for cryptographic verification. Tested end-to-end on Azure DCasv5 (AMD SEV-SNP) against Microsoft Azure Attestation. Fail-closed — if the service is unreachable or verification fails, nodes are marked tee-attested=false and the scheduler won’t place confidential workloads there. The scheduler enforces attestation freshness and trust anchor matching, so a node can’t coast on a stale or wrong-anchor attestation.
An admission webhook that prevents label spoofing. Fail-closed.
A compliance report CLI that reads the scheduler’s structured audit logs — which nodes were considered, which were rejected and why — and generates HIPAA, SOC2, and GDPR artifacts without needing cluster access.
With Nexa, the compliance officer’s question has an answer. “Can you prove workload X never ran on the same node as workload Y?” Yes — here’s the structured audit log with timestamps, node IDs, attestation results, rejection reasons, and the policy that drove each decision. The compliance report CLI generates the HIPAA, SOC2, or GDPR artifact without needing cluster access. Honestly, the audit trail is the real product. The scheduler is just the automation.
An Uncomfortable Gap
Nexa isn’t magical, though (maybe that will take me two days). GPU VRAM sits outside the CPU TEE protection boundary. Nexa’s confidential compute plugin correctly places pods on verified TDX/SEV-SNP nodes — but GPU computations are exposed. The compliance report is technically accurate about placement. It’s misleading about execution. I documented this as accepted risk #9 in the threat model rather than pretend it doesn’t exist. The next phase enforces node-level GPU exclusivity — one org per GPU node, full stop — so that Nexa’s existing node isolation model covers GPU workloads without claiming per-device protections that don’t exist yet. A scheduler can’t fix a hardware limitation. But it can refuse to claim something it can’t prove.
The Arc
This is the fourth thing I’ve written in the PM in the AI Era series, and I think the arc is finally visible.
First, I was a bored PM who discovered he could build again — an end-to-end encrypted task manager, 12,000 lines of TypeScript, agent teams doing the implementation while I did the product thinking. The feeling wasn’t just “AI is powerful.” The more exciting feeling was “I’m not bored anymore.”
Then I realized the workflow was duct tape, so I built Flowstate — a sprint framework that treats agents like athletes. Train, measure, adjust. Skills, gates, retrospectives.
Then I tested it honestly and found out that most of what I’d built was overhead. Gates matter. Sprint structure matters for large scope. Everything else is optional. The uncomfortable punchline: raw Claude Code with no framework produces comparable quality for well-scoped work.
Now this. Nexa is the first project where I used what I’d learned — gates, light structure, no ceremony — on a genuinely hard infrastructure problem. Eighteen sprints, maybe three hours of my actual attention2 inside a 10-hour wall clock. Claude Code ran 1,968 API calls, spawned 47 subagents, and passed quality gates on the first attempt in 14 of 17 sprints. I wrote the PRD and the roadmap. The agent wrote 12,900 lines of Go. Nexa is one of six projects I’ve shipped in the last two weeks — an encrypted task manager (Olm/Megolm crypto, WebAuthn, WASM-sandboxed agents), a security evaluation CLI (static analysis that verifies security claims match implementation), a Claude multi-agent sprint framework (gates, metrics, tested across 19 sprints), an encrypted runbook runner (local-first, eval-based validation), a P2P encrypted messenger over Tor (Noise + Olm double encryption, Rust/tokio), and now a Kubernetes scheduler.
The throughline across these projects isn’t “I can write code fast with AI.” It’s that I’m learning the role of a PM in this era — define the constraints, evaluate the proposals, accept or override. But I’m a PM, not a scheduler maintainer. If the Filter/Score plugin has a subtle concurrency bug, or if the node state controller’s informer cache has an ordering assumption that breaks under real churn, I probably wouldn’t catch it in code review. The quality gates catch what they can — syntax, type errors, behavioral regressions in the test suite — but they don’t catch architectural mistakes the tests don’t know to look for. An experienced Kubernetes systems engineer would likely find issues I missed.
What’s changed is that I’m no longer just handing those engineers a PRD and some wireframes. I’m handing them four binaries, Helm charts, 11 documented threats with mitigations, a scaling analysis that tells you where the architecture breaks, and a test suite that proves the core invariants hold. (Terminal-level verification here.) Not production-hardened — nobody’s paged me at 3 AM because a privacy label race dropped a pod on the wrong node — but Nexa is a running start instead of a slide deck.
There are plenty of people who can build schedulers. What’s scarce is the person who reads a NIST framework and a Kubernetes SIG proposal on the same morning and sees the product that should exist at their intersection — then builds it before dinner.
The only limit now is noticing.
Appendix: What Breaks at Scale (and Where This Goes)
I am a PM so I can’t leave you with the impression this product is finished. The architecture works cleanly below 100 nodes. Beyond that, honest problems emerge. (Full analysis in the repo.)
Tier 1 (under 100 nodes): Works as-is, but cache parsed policy objects (the current code re-parses JSON eight times per pod per scheduling cycle — embarrassing) and add a spec.nodeName informer index so the controller stops scanning all pods on every reconciliation.
Tier 2 (100–500 nodes): Leader election on controllers, or multiple replicas cause label patch races. Parallel TEE attestation — sequential verification across 100 nodes at 200ms each takes 20 seconds per tick. Server-Side Apply instead of MergePatch for atomic updates.
Tier 3 (500–2,000 nodes): An eventual consistency race starts to matter. Pod terminates on node X, scheduler places a new high-privacy pod before the controller marks wiped=false. Privacy guarantee violated. You need a PreFilter gate that checks real-time node state, accepting one extra API call per sensitive scheduling cycle.
Tier 4 (2,000+ nodes): Fundamental changes. Node state moves from labels to a dedicated CRD. Scheduler sharding. Async audit pipeline. At this point, you’re building a standalone gRPC policy service that any scheduler — Kubernetes, Slurm, YARN — can call. That’s the real endgame.
Footnotes
Footnotes
-
Representative tests that assert on behavior, not just coverage: a high-privacy pod from
acmeis rejected from a node running anevil-corpworkload (org isolation); a confidential pod is rejected from a node withtee-attested=false(attestation enforcement); a pod requestingus-west1is rejected from aneu-west1node (data residency); the node controller markswiped=falseafter a pod completes (contamination tracking); and the webhook rejects a pod claimingorg=alphain namespacebeta-workloads(label spoofing prevention). ↩ -
Measured from Claude Code session logs. Across 20 sessions, I sent 121 substantive prompts (filtered from 2,062 total interactions — the rest were tool permission approvals). Total time composing those prompts — the gap between Claude finishing a response and me sending the next real instruction — was 145 minutes. Add ~20 minutes for writing the PRD before the first session. That’s ~2.75 hours of reading and prompt composition. The agent’s autonomous runtime was about 5 hours across 18 sprints (average 17 minutes each). The rest of the 10-hour wall clock was gaps between sessions where neither of us was working. ↩